Oracle Optimizer의 원리 이해 및 SQL & 애플리케이션의 튜닝(하)
Oracle Basic
2005/04/28 14:15
http://blog.naver.com/ratm7804/140012373274
Oracle Optimizer의 원리 이해 및 SQL & 애플리케이션의 튜닝(하):
오라클의 튜닝 기법의 100% 활용
지난 회에서는 튜닝에 들어가기 위해 먼저 Oracle Optimizer의 원리와 특징에 대해서 설명했다.
이번 회에서는 조인 메소드별 특징과 플랜 보는 법을 이해하고, 실제 오라클에서 제공하는 튜닝 기법들을 활용해 보도록 하자.
숲을 보는 튜닝
튜닝에는 정답이 없다. 즉 튜닝은 시스템의 특징이나 업무의 특징들을 정확히 이해하고, 그 상황에 맞게 문제의 원인을 확인하고, 문제의 원인을 해결하기 위한 최적의 튜닝 방법을 찾아야 한다는 것이다.
튜닝의 기본 목표는 자원을 상황에 맞게 효율적으로 사용해서 원하는 결과값을 원하는 시간 내에 받아보는 것이다. 병렬 기능을 많이 사용한다고 해서 항상 좋은 결과가 나오는 것은 아니다. 또한 시스템의 자원은 한정되어 있다는 것을 항상 명심해야 한다. 하나의 애플리케이션이 한정된 시스템 자원을 병렬 기능을 사용해서 독점한다면, 다른 애플리케이션들은 상대적으로 피해를 보게 되는 것이다. 즉 튜닝은 하나의 애플리케이션을 위한 것이 아니라 모든 애플리케이션이 조화롭게 운영될 수 있도록 하여야 한다는것이다.
이런 입장에서 필자는 나무를 보지 말고 숲을 보라고 항상 강조한다. 즉 단위 SQL 문장의 플랜(plan) 튜닝도 중요하지만, 전체적인 조화를 이루는 SQL 문장의 유형 및 구조적인 문제 등이 더 중요하다는 것이다. 업무 시작 이후에 구조적인 문제를 해결하려면 상당한 인적, 시간적 자원을 소모해야 하지만, SQL 문장의 플랜적인 튜닝은 해당SQL 문장의 튜닝결과를 적용하는 것으로, SQL 문장의구조적, 유형적 튜닝에 비해 상대적으로 적은 비용이 들 것이다. 그래서 튜닝 작업을 이런 측면에서 바라보도록 항상 노력하여야 할 것이다.
조인 메소드별 특징
오라클의 조인 메소드는 Nested Loop Join(NLJ), Sort Merge Join(SMJ), Hash Join(HJ)의 3가지가 있다. 이들 3가지 조인 메소드로 여러 조인 타입 (Basic(natural) Join, Outer Join, Semi Join, Anti Join 등)을 지원하게 된다. Oracle Optimizer는 최적화 단계에서 이들 조인 메소드들 중 조인에 대한Selectivity와Cardinality의 계산에 의해 가장 효율적인 것을 선택하게된다. 단 RBO(Rule Base Optimizer)에서는 인위적인 힌트(USE_HASH)를 주지않고서는 Hash Join은 전혀 고려하지 않는다. 힌트를 준 것 자체가 이미 RBO가 아니라 CBO(Cost Base Optimizer)로 동작되는 것이다.
조인을 확인할 때 조인 메소드 뿐만 아니라 조인 순서 또한 중요하다. 먼저 액세스 되는 쪽을 ‘드라이빙테이블(Driving Table) ’ 이라고 하며, 나중에 액세스되는 테이블을‘이너 테이블(Inner Table)’이라고 한다. Hash Join 에서는‘Build Table’과‘Probing Table’이라는 용어로 사용된다. SQL 문장에서 튜닝을 잘 하기 위해서는 조인 메소드별 특징을 정확히 이해하고 플랜을 통해 처리되는 과정을 그려볼 수 있어야 한다.
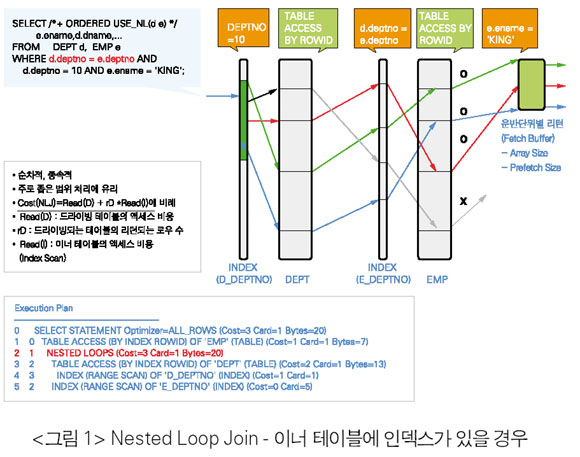
Nested Loop Join(NLJ)
• NLJ는 순차적인 처리로Fetch의 운반단위(Array Size, Prefetch Size)마다 결과 로우(row)를리턴 받을 수 있다.
• 첫 번째 로우를 받는 시간은 빠르나, 전체 결과 로우를 받는 데까지 걸리는 시096 ORACLE KOREA MAGAZINE 간은 느리다. 즉 첫 번째 로우를 받을 준비가 되어 있는 단계까지를 실행시간으로 볼 때 실행시간은 빠르나 Fetch 시간은 느리다.
• NLJ는 메모리가 필요 없는 조인이다. 그러므로 추가적인 메모리 비용이 필요없다.
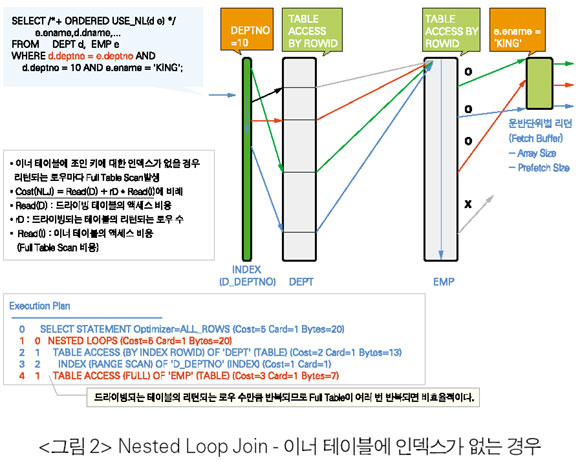
• NLJ는 드라이빙 테이블에서 많은 로우들이 필터링되어 이너 테이블로 찾아 들어가는 부분을 줄여야 하므로 드라이빙 순서가 중요하다.
• 이너 테이블은 드라이빙 테이블의 리턴되는 모든 로우들에 대해서 반복 실행하므로 액세스 효율이 좋아야 한다. 즉 대부분의 경우 이너 테이블은 인덱스가 있어야 한다. 또한 인덱스의 효율이 좋아야 한다. 이너 테이블이 작더라도 액세스 횟수가 많다면 인덱스가 있어야 한다. 인덱스의 효율이 좋지 않아 전체의 Index Range Scan과 같은 경우는 최악의 조건이다.
• NLJ는 주로 인덱스 위주의 싱글 블록 I/O의랜덤I/O 위주이므로OLTP에서 적은 데이타 범위 처리에 주로 사용된다. 즉 전체의 15% 이상의 경우는 Full Table Scan을 이용한 Sort Merge 또는 Hash Join을 이용한다.
• NLJ도 드라이빙 테이블이 Full Table Scan에 병렬로 처리되면 이너 테이블도 병렬로 종속적으로 처리된다.
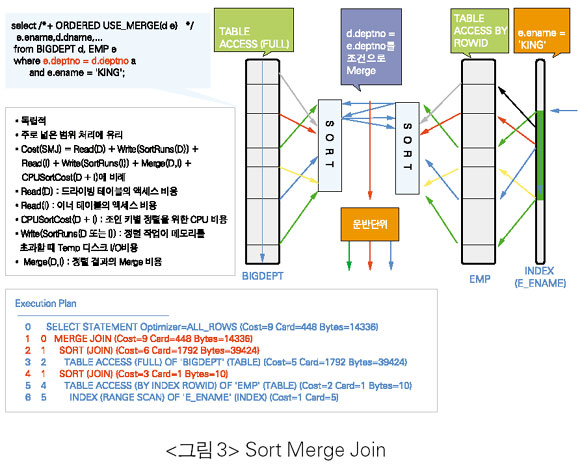
Sort Merge Join(SMJ)
• 전체 로우를 리턴 받는 시간이 빠르다. 즉 첫 번째 로우를 리턴 받을 준비까지의 시간은 느리지만, 준비가 된 상태에서의 Fetch 시간은 빠르다(메모리에서 리턴하므로). 이는 대상 로우들(Where 조건에 의해 필터된 로우들만 정렬)을 가지고 정렬 작업(모든 로우들을 조인 키로 정렬)을 하기 전까지는 어떠한 로우도 리턴할 수 없기 때문이다.
• NLJ와같이 드라이빙 테이블의 리턴되는 로우 수와 이너 테이블의 액세스 패턴에 의에 액세스 효율이 좌우되지 않으며, 조인 테이블 간에 자신의 처리범위로만 처리량을 결정하므로 독립적이다.
• 추가적인 정렬 메모리(SORT_AREA_SIZE) 비용이 필요하다. 메모리가 부족하면 TEMP 테이블스페이스에 정렬 중간단계(Sort Runs)를 기록하게 되므로 추가적인 디스크 I/O비용이 발생할 수 있다.
• 정렬 메모리에 위치하는 대상은 조인 키뿐만 아니라 Select List도 포함하므로 불필요한 Select List는 제거해야 한다.
• 정렬 작업의 CPU 사용에 대한 오버헤드가 있다. 그러므로 많은 로우들과 전체적으로 Select List의 사이즈의 합이 큰 테이블의 조인에는 문제가 있다. 즉 디스크 정렬을 피할 수가 없으며, 정렬에CPU 비용이 많이 든다.
• 디스크 정렬만 발생하지 않는다면 넓은 범위 처리에 유리하다.
• 디스크 정렬을 피할 수 없는 경우라면(Batch Job, Create index,...)
SORT_AREA_SIZE , SORT_MULTIBLOCK_READ_COUNT를SQL마다 세션 레벨에 할당해서 사용하도록 한다(WORKAREA_SIZE_POLICY가 Manual일 경우나 Oracle9i Database 이전 버전에서). 또한TEMP 테이블 스페이스의 Extent Size도 충분히 크게 주도록 한다.
• 정렬 메모리의 크기는 (= Target rows×(total selected column’s bytes)×2) 이상 설정하되, PGA의 메모리 한계로 인해 테스트를 통해 PGA Memory Allocation Error가 발생하지 않는 범위 내에서 설정하도록 한다. 필요시 10032 Trace를 이용해 점검한다.
ALTER SESSION SET EVENTS ‘10032 TRACE NAME CONTEXT FOREVER’;
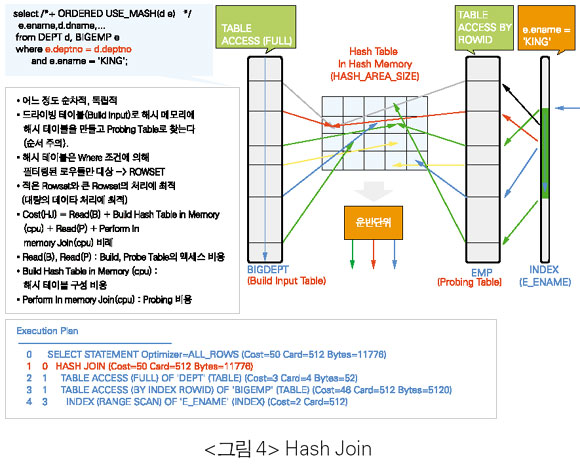
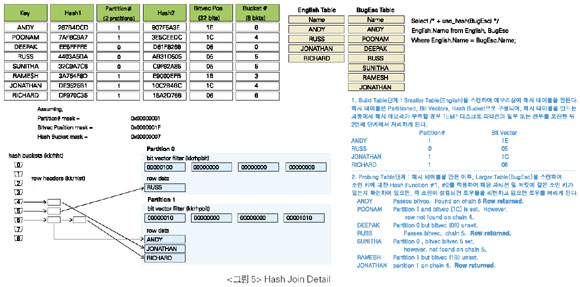
Hash Join(HJ)
• Hash Join은 두 개의 조인 테이블 중Small Rowset(Where 조건에 의해 필터링된 로우 수가 작은 테이블)을 가지고 HASH_AREA_SIZE에 지정된 메모리 내에 해시 테이블을 만든다.
• 해시 테이블을 만든 이후부터는NLJ의 장점인 순차적인 처리 형태이다. 그러므로NLJ과SMJ의 장점을 가지고 있다.
• Hash Join은 Basic Join( ‘=’)만 가능하다.
• NLJ와같이 드라이빙 테이블의 리턴되는 로우 수와 이너테이블의 액세스 패턴에 의에 액세스의 효율이 좌우되지 않으며, 조인 테이블 간에 자신의 처리 범위로만 처리량을 결정하므로 독립적이다.
• SMJ의 단점인 많은 로우들의 처리 또는 전체적으로 Select List의 사이즈의 합이 큰 테이블의 조인시 정렬 작업의 CPU 사용에 대한 오버헤드 및 디스크 정렬과 같은 문제점은 없다. 그러므로 최소한SMJ보다는 우수하다.
• 한 테이블은 작은 Rowset 사이즈(리턴되는 로우 수와 Select List 기준), 다른 한 테이블은 아주 큰 사이즈의 조인에 유리하다. 이러한 경우는 반드시 작은 사이즈를 가지고 해시 테이블을 만들어야 한다. 단, Hash Join은 순서가 매우 중요하다는 점에 주의하는데, 작은 Rowset으로 해시 테이블을 만들어야 하기 때문이다.
• 힌트를 잘못 주어서 Big Rowset이 리턴되는 테이블부터 드라이빙된다면(Build Table), HASH_AREA_SIZE의 메모리 부족으로 TEMP 디스크 I/O가 발생한다. 그러므로 힌트를 줄 경우 반드시 드라이빙 순서를 정확히 주어야 한다.
• 디스크 I/O를 피할 수 없는 경우라면, HASH_AREA_SIZE(default : =SORT_AREA_SIZE×2)를 SQL마다 세션 레벨에 할당해서 사용하도록 한다(WORKAREA_SIZE_POLICY가 Manual일 경우이거나 Oracle9i Database 이전 버전에서). 또한TEMP 테이블스페이스의 Extent Size도 충분히 크게 주도록 한다. HASH_MULTIBLOCK_IO_COUNT는 옵티마이저에게 자동 조정하도록 설정하지 않는다.
• 해시 메모리의 사이즈는 (= Small Table의 Target rows×(total selected column’s bytes)×1.5) 이상 설정하되, PGA의 메모리의 한계로 인해 테스트를 통해 PGA Memory Allocation Error가 발생하지 않는 범위 내에서 설정하도록 한다. 필요시 10104 Trace를 이용해 점검한다.
ALTER SESSION SET EVENTS ‘10104 TRACE NAME CONTEXT FOREVER’;